Google Cloud Next ’26:TPU 8t 与 TPU 8i 双芯发布,训练与推理分工,算力效率较上代最高提升 3 倍
-
Google 在 Cloud Next ’26 大会上宣布推出第八代 TPU,分为两款独立架构:TPU 8t(专注训练)和 TPU 8i(专注推理),均将于今年晚些时候正式发布。
TPU 8t:训练利器
单个 TPU 8t 超级 Pod 可扩展至 9,600 颗芯片、2 PB 共享高带宽内存,提供 121 ExaFlops 算力,计算性能较上代提升近 3 倍。同时集成 10 倍更快的存储访问,并通过 Virgo 网络与 JAX/Pathways 软件支持最多百万芯片的近线性扩展。
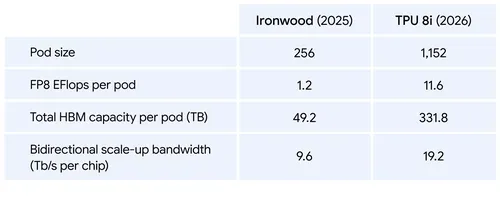
TPU 8i:推理引擎
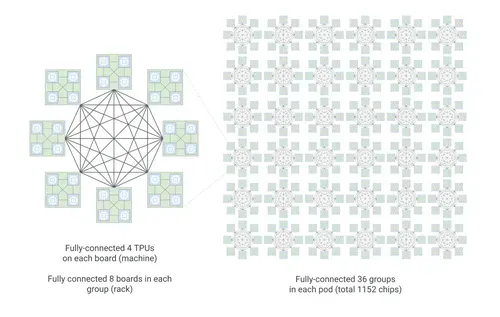
TPU 8i 搭载 288 GB 高带宽内存与 384 MB 片上 SRAM(较上代增加 3 倍),ICI 互连带宽提升至 19.2 Tb/s,新增片上集合加速引擎(CAE)将延迟降低最多 5 倍。整体性能每美元效率提升 80%,相同成本下可服务近两倍的用户量。
能效与系统协同
两款芯片均采用 Google 自研 Axion ARM CPU 主机,性能每瓦功耗较上代 Ironwood 提升最多 2 倍,并配备第四代液冷技术,支持原生 JAX、PyTorch、SGLang、vLLM 等主流框架。